PREDICTION SYSTEM
予測システム

特許の審査結果(進歩性)を予測する
当事務所の強み(拒絶理由通知についてのご相談ページ)に記載されているように、審査官は、発明と先行技術との違いを距離に置き換えて考えています。これをヒントに”発明と先行技術との違いをコンピュータで計算できる”、との着想を得て、AI(機械学習)を活用した進歩性の予測技術を発明しました(特許第6308706号他4件)。
通知される拒絶理由の大半が進歩性ですので、進歩性があるのかどうかがわかれば、その発明の審査結果が予測でき、拒絶理由通知が来るのかどうかがわかる、ということになります。
審査結果が予測できると、下記A)、B)のような場面で特許実務の効率化が期待できます。
A)出願前に予測を行い、必要な修正後に出願することで、権利化の可能性を高める
B)審査請求の前に予測を行い、進歩性有りなら審査請求、進歩性無しなら審査請求を見送り
予測のための機械学習部
機械学習部は、実際の拒絶理由通知を用いた学習データで下の図のように学習されています。
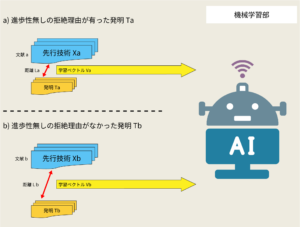
進歩性無しの拒絶理由通知では、審査されている発明との関連性が最も高い先行技術(正確には文献)が引用されます。上の図のa)のように、発明Taについて、これと関連性が最も高い先行技術Xaの文献(文献a)が引用されます。発明Taと先行技術Xaとの違いに応じた距離Laが想定されますが、距離Laは距離LV(進歩性有りとなる距離。詳しくは当事務所の強み)に至らない大きさなので、小さい大きさになります。
拒絶理由通知では、進歩性無しの拒絶理由が通知されないこともあります。この場合、その発明には進歩性が有ったため、上の図のb)のように、発明Tbと、先行技術Xbとの違いに応じた距離Lbは距離LVと遜色の無い大きさであって大きくなります。
距離LVは、仮想的なもので算出することは困難ですが、実際のa),b)のタイプの拒絶理由通知は複数有り(特にa)のタイプ)、これらを学習させることで距離La、距離Lbの大まかな目安を求めることができます。
距離La、距離Lbの大まかな目安を学習させるべく、機械学習部では、実際の拒絶理由通知を用いて距離La、Lbのそれぞれに応じた学習ベクトルVa,Vbが作成され、それを用いた機械学習が行われています。
この機械学習部に予測したい発明と、先行技術との違いに応じたベクトルを入力し、それが距離La、Lbのどちらに分類されるのかによって進歩性の無し、有りが判断されることになります。
機械学習部を用いた予測の有用性
距離LVを実務経験を通じて体得できたとしても、それは、”カン”のような形でしか捉えられません。
そのため、進歩性の判断は”職人技”のような側面がとても強く、結果に客観性、均質性を持たせることが困難ですし、結果を出すのに手間を要するため、効率化も困難です。この点、機械学習部を用いた予測には客観性、均質性があり、作業の機械化による効率化も期待できます。そのため、機械学習部を用いた予測を取り入れることで、人的、時間的な資源の有効活用を図り、余裕のできた人的、時間的な資源を”職人技”というべき判断に振り向けて堅実な対応を推進することが可能となります。
予測の仕方
予測しようとするときは、下の図のように、予測対象の発明が記載されている文書(案文書)と、その相手となる先行技術を指定(指定先行技術)します。
システムで、案文書と、指定先行技術から、それぞれの発明を特定するためのテキストデータを抽出して双方に応じた入力ベクトルを生成し、その入力ベクトルを機械学習部に入力します。すると、機械学習部が入力ベクトルを距離La、距離Lbのどちらかに分類し、その分類結果から、進歩性の無し、有りを判定して予測結果として出力します。